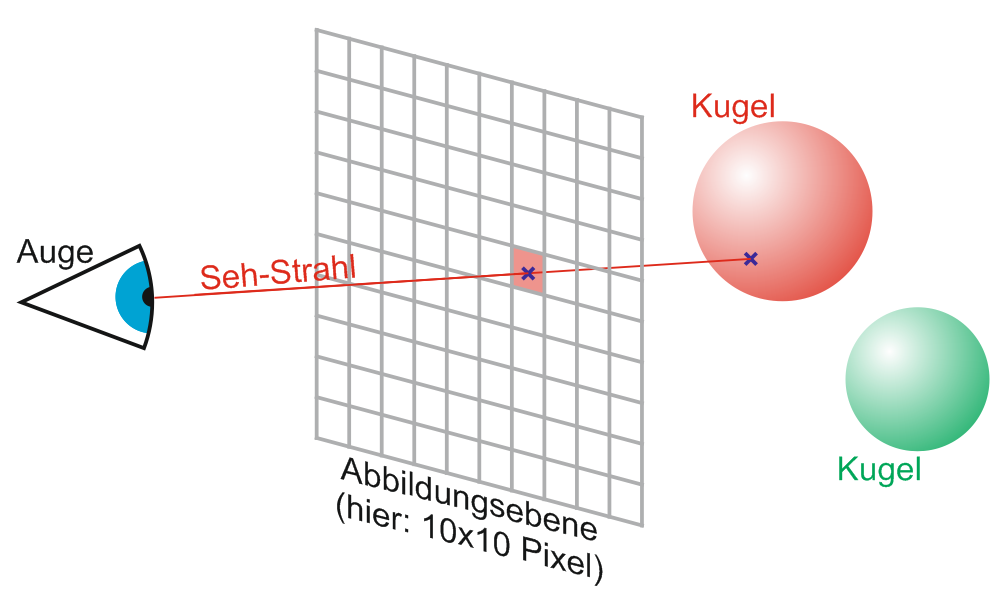
Im ersten Teil dieser Artikelreihe haben wir uns mit den Grundlagen des Raytracings beschäftigt und Schnittstellen definiert, welche die einzelnen Softwarekomponenten bzw. ihre Funktionalität beschreiben. Wir werden im Folgenden eine der wichtigsten Komponente entwickeln: Die Kamera.
Aufgabe der Kamera ist es eine Bitmap-Grafik von einer Szene zu rendern. Sie sendet dazu für jeden Pixel einen Ray durch die Szene und ermittelt so, auf welches Primitiv der jeweilige Ray trifft. Der Pixel bekommt dann die Farbe des Primitivs. Weiterhin untersucht die Kamera die Ausrichtung der Fläche, auf der ein Ray endet, zum Licht und hellt den Pixel entsprechend auf, oder dunkelt ihn ab.
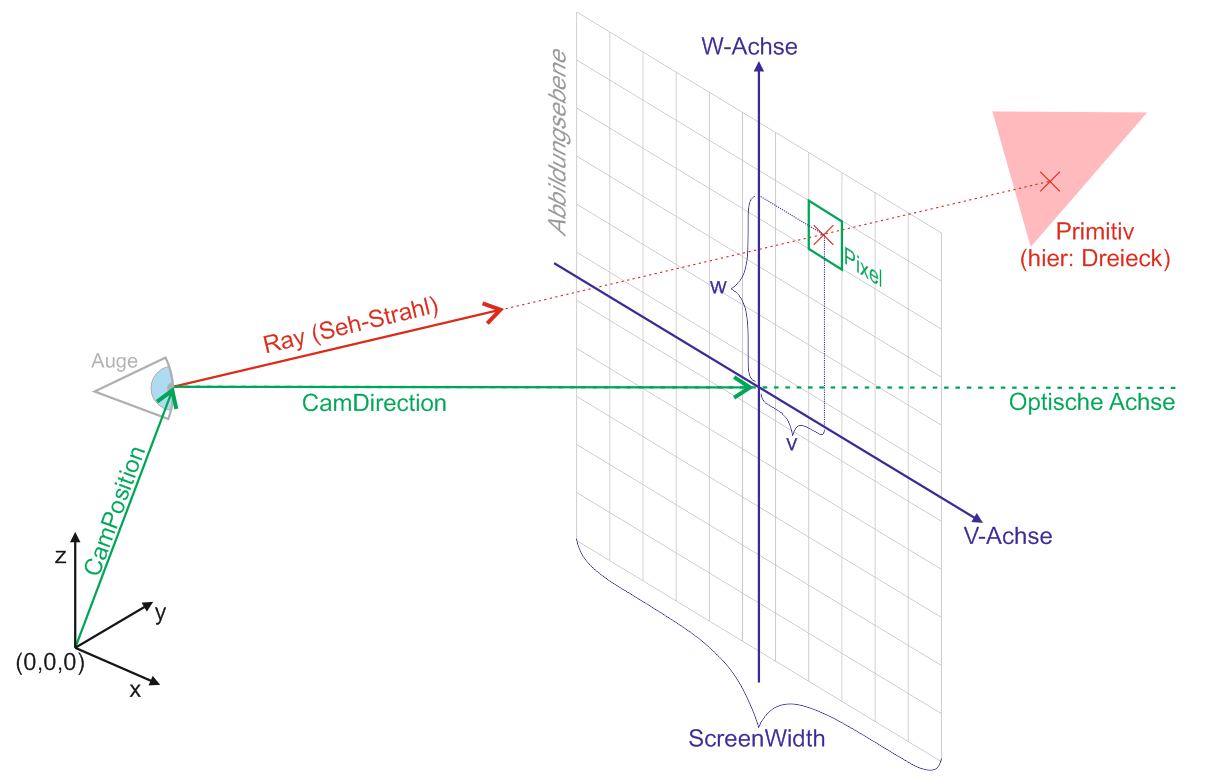
Eine Kamera hat eine Position im Raum, welche durch den Vektor CamPosition beschrieben wird. Weiterhin hat sie eine Blickrichtung, welche durch den Vektor CamDirection beschrieben wird. Die Länge des Vektors CamDirection entspricht dem Abstand der Abbildungsebene von der CamPosition. Um einer Verwechselungsgefahr mit dem dreidimensionalen Koordinatensystem x, y, z vorzubeugen, wollen wir die zweidimensionalen Koordinaten auf der Abbildungsebene nicht mit x und y sondern mit v und w bezeichnen. Die CamPosition befindet sich genau senkrecht über dem Nullpunkt (v=0, w=0) der Abbildungsebene. Eine Längeneinheit auf der Abbildungsebene entspricht genau einem Pixel. Der im Bild grün hervorgehobene Pixel hat also die Koordinaten (v=2, w=4). Da der Nullpunkt der Abbildungsebene hier genau in der Mitte des Bildes (und nicht wie sonst üblich in der oberen linken Ecke) liegt, können die Koordinaten eines Pixels auch negativ sein.
Die Klasse RayTraceCamera
Wir erstellen nun die Klasse RayTraceCamera. Im Konstruktor bekommt diese Klasse unter anderem ein IRayTraceable übergeben. Dies ist die Szene, in der sich alle Primitive befinden. Wie im vorhergehenden Teil beschrieben enthält das Interface IRayTraceable alle Methoden, die wir benötigen um die Szene mit Strahlen bzw. Rays zu untersuchen und daraus ein Bild zu rendern. Wie diese Methoden der Szene genau implementiert werden, soll uns an dieser Stelle zunächst egal sein. Weiterhin bekommt der Konstruktor der RayTraceCamera die Position und Blickrichtung der Kamera übergeben.
public class RayTraceCamera
{
IRayTraceable scene;
Vector3D camPosition;
Vector3D camDirection; // Direction Vector with Length = eyeDistanceToScreen
Vector3D camDirectionNorm; // Normalized Direction Vector
Vector3D upDirection = Vector3D.eY; // Richtung nach oben
const double eyeDistanceToScreen = 1.5; // Abstand des Auges zur Abbildungsebene in Längeneinheiten des XYZ-Koordiantensystems
const double screenWidth = 1; // Die Breite der Abbildungsebene in Längeneinheiten des XYZ-Koordiantensystems
Vector3D eV; // Einheitsvektor in V-Richtung (horizontal) der Screen Ebene mit der Länge 1px
Vector3D eW; // Einheitsvektor in W-Richtung (vertikal) der Screen Ebene mit der Länge 1px
int screenWidthPx = 300;
int screenHeightPx = 200;
public RayTraceCamera(IRayTraceable scene, Vector3D camPosition, Vector3D camDirection)
{
this.scene = scene;
MoveTo(camPosition, camDirection);
}
public void MoveTo(Vector3D position, Vector3D direction, Vector3D upDirection = null)
{
if (upDirection != null) this.upDirection = upDirection.normalize(); // wenn null, bleibt die upDirection unverändert
camPosition = position;
camDirectionNorm = direction.normalize();
camDirection = camDirectionNorm * eyeDistanceToScreen; // direction-Länge auf eyeDistanceToScreen ändern
Init();
}
public void ResizeScreen(int widthPx, int heightPx)
{ // Größe des gerenderten Bild in Pixeln setzen
screenWidthPx = widthPx;
screenHeightPx = heightPx;
Init();
}
private void Init()
{
eV = camDirectionNorm.cross(this.upDirection);
eW = eV.cross(camDirectionNorm);
eV = eV * (screenWidth / screenWidthPx); // Länge auf 1px ändern
eW = eW * (screenWidth / screenHeightPx); // Länge auf 1px ändern
}
}
Betrachten wir zunächst die Klassenvariablen: „scene“, „camPosition“ und „camDirection“ wurden bereits erwähnt und werden hier nicht weiter erläutert. Der Vektor „camDirectionNorm“ zeigt in die gleiche Richtung wie „camDirection“, er bekommt jedoch stets die Länge 1. Bisher haben wir nicht berücksichtigt, wie die Kamera seitlich geneigt ist (Rollwinkel). Um ein Bild zu Rendern brauchen wir jedoch diese Information (schließlich könnte die Kamera auch auf dem Kopf stehen). Daher gibt es den Vektor „upDirection“ der festlegt, wo in der Szene oben sein soll. Dieser Vektor wird mit dem Einheitsvektor eY vorbelegt. Im allgemeinen ist es nicht notwendig diesen Vektor zu ändern – auch dann nicht, wenn die Kamera nach unten oder oben geneigt wird. Die Konstante „eyeDistanceToScreen“ definiert den Abstand des Auges zur Abbildungsebene. Sie entspricht der Brennweite des Kameraobjektivs. Würde man den Wert vergrößern, so würde man in die Szene hineinzoomen. Die Länge des Vektors „CamDirection“ wird, wenn die Blickrichtung der Kamera geändert wird, stets an diesen Wert angepasst.
Die Konstante „screenWidth“ definiert, wie breit die Abbildungsebene in Längeneinheiten des XYZ-Koordinatensystems ist. Wenn wir diesen Wert durch die Anzahl der Bildbreite in Pixeln dividieren, erhalten wir die Größe eines Pixels im XYZ-Koordinatensystem.
Für unsere Berechnungen benötigen wir weiterhin zwei Vektoren, welche die Abbildungsebene selbst aufspannen, also der V und W-Achse entsprechen. Wir definieren daher noch die Einheitsvektoren eV und eW, welche parallel zur V bzw. W-Achse verlaufen und die Länge 1 Pixel haben.
In der Klasse RayTraceCamera befinden sich bereits die beiden public-Methoden „MoveTo“ und „ResizeScreen“, mit denen der Ort und die Blickrichtung der Kamera sowie die Größe des zu rendernden Bitmaps geändert werden kann. Beide Methoden rufen am Ende die Methode „Init“ auf, welche die Einheitsvektoren eV und eW neu berechnet. Da der Vektor eV immer horizontal liegen soll, wird er aus dem Kreuzprodukt der Kamera-Blickrichtung und der nach-oben-Richtung gebildet.
Weitere RayTraceCamera-Methoden
Wir werden nun die RayTraceCamera um noch ein paar Methoden erweitern. Aus dem Bild zu Beginn dieses Artikels können wir entnehmen, dass wir jedem Pixel (bzw. jeder VW-Koordinate) einen Ray zuordnen können. Der Startpunkt jedes Rays ist die CamPosition. Seine Richtung ist eine Linearkombination aus der CamDirection und den Vektoren eV und eW. Die Methode „VWtoRay“ gibt den zu einer VW-Koordinate gehörenden Ray zurück:
public Ray VWtoRay(double v,double w)
{
return new Ray(camPosition, camDirection + eV * v + eW * w);
}
Als nächstes erstellen wir die Methode „AdjustColor“. Sie bekommt eine Farbe und einen Helligkeitswert (brightness) übergeben und liefert eine neue Farbe zurück. Wenn brightness == 0 ist, entspricht die zurückgegebene Farbe genau der übergebenen Farbe. Ist brightness > 0 wird die Farbe aufgehellt, ist brightness < 0 wird sie abgedunkelt. Der Wert für brightness muß immer zwischen -1 und 1 liegen.
static Color AdjustColor(Color c, double brightness)
{
if (brightness >= 0)
return Color.FromArgb( // Die Farbe aufhellen
c.R + (int)((255 - c.R) * brightness),
c.G + (int)((255 - c.G) * brightness),
c.B + (int)((255 - c.B) * brightness)
);
else // if brightness < 0
return Color.FromArgb( // Die Farbe abdunkeln
(int)(c.R * (1 + brightness)),
(int)(c.G * (1 + brightness)),
(int)(c.B * (1 + brightness))
);
}
Die Farbe eines Pixels berechnen
Kommen wir nun zu der kompliziertesten Methode der Kamera: Die Methode „ColorAt“ soll die Farbe eines Punktes mit den Koordinaten v und w berechnen.
static readonly double minDistToRayStart = 1E-10;
Color ColorAt(double v, double w)
{
Ray ray = VWtoRay(v, w);
PointOnPrimitive p = scene.RayTrace(ray);
if (p == null)
return scene.Background; // Wenn der Ray auf kein Primitiv trifft, Hintergrundfarbe der Szene zurückgeben
else
{ // Prüfen, ob der PointOnPrimitive im Schatten liegt
Ray rayToSun = new Ray(p.ToPointInSpace() + scene.DirectionToSun * minDistToRayStart, scene.DirectionToSun);
if (scene.RayTraceHits(rayToSun)) return AdjustColor(p.GetColor(), scene.MaxDarkening); // Wenn keine freie Sicht auf die Sonne => Schatten
Vector3D n = p.GetNormal(); // Muß die Länge 1 haben!
if (n == null) return p.GetColor(); // Wenn keine Normale berechnet werden kann, Originalfarbe zurückgeben
// Die Normale muß eine Komponente in Richtung des Betrachters haben. Sie darf nicht von ihm weg zeigen.
if (ray.Direction * n > 0) n = n.opposite(); // Wenn das Skalaprodukt > 0 ist, ist der Winkel kleiner als 90° und wir drehen den Vektor um.
double brightness;
double cosAngleToLight = scene.DirectionToSun * n;
if (cosAngleToLight > 0)
brightness = scene.MaxDarkening + (scene.MaxLightening - scene.MaxDarkening) * cosAngleToLight; // Es fällt Licht auf die Fläche
else
brightness = scene.MaxDarkening; // Es fällt kein Licht auf die Fläche
return AdjustColor(p.GetColor(), brightness);
}
}
Die Methode „ColorAt“ ermittelt zuerst mit „VWtoRay“ einen Ray, den sie mit „scene.RayTrace“ durch die Szene sendet. Wenn der Ray auf kein Primitiv trifft, kann man an dieser Stelle durch die Szene hindurch sehen, und die Hintergrundfarbe „Scene.Background“ wird zurück gegeben. Wenn der Ray auf ein Primitiv trifft, wird ein PointOnPrimitive ermittelt. Wir prüfen zunächst, ob der PointOnPrimitive im Schatten liegt, indem wir ausgehendend von seinen XYZ-Koordinaten einen neuen Ray „rayToSun“ Richtung Sonne senden. Trifft dieser Ray auf ein Primitiv, d.h. Scene.RayTraceHits(rayToSun) == true, so wird die Farbe des PointOnPrimitives maximal mit dem Wert Scene.MaxDarkening abgedunkelt und dieser Farbwert von „ColorAt“ zurückgeliefert. Es fällt auf, dass der Startpunkt von „rayToSun“ beim Erstellen des Rays ein beliebig kleines Stück der Länge minDistToRayStart in Richtung Sonne verschoben wird. Dies geschieht, damit beim Raytracen zur Sonne nicht wieder das Primitiv selbst gefunden wird und ein Primitiv sich nicht sozusagen selbst in den Schatten stellt.
Wenn der PointOnPrimitive nicht im Schatten liegt, müssen wir aus dem Winkel seiner Oberfläche und der Beleuchtungsrichtung bestimmen, wie hell dieser ist. Eine Fläche, die genau senkrecht zum Sonnenlicht steht, wird mit dem maximalen Wert „Scene.MaxLightening“ aufgehellt. Wir fragen den PointOnPrimitive zunächst mit „p.GetNormal()“ nach seinem Flächennormalenvektor „n“ (einem Vektor, der senkrecht auf der Fläche steht). Da eine Fläche zwei Seiten hat, gibt es zwei (gegenüberliegende) Richtungen, in die dieser Vektor zeigen kann. Eine dieser Richtungen hat eine Komponente in Richtung der Kamera. Die andere zeigt von der Kamera weg. Wir wollen nur die Vektorrichtung haben, welche in Richtung der Kamera zeigt. D.h. wenn der Winkel zwischen Kamerarichtung und dem Normalenvektor kleiner als 90° ist (ray.Direction * n > 0), drehen wir den Vektor mit „n.opposite()“ um.
Wir berechnen nun den Kosinus „cosAngleToLight“ aus dem Winkel zwischen dem Normalenvektor n und der Sonnenrichtung. Ist der Kosinus größer als 0 bzw. der Winkel kleiner als 90°, so fällt Licht auf die Fläche und wir berechnen aus dem Kosinus die brightness. Wenn die Fläche von der Sonne abgewendet ist (cosAngleToLight <0), fällt dagegen kein Licht darauf und wir wählen die maximale Abdunkelung „Scene.MaxDarkening“.
Das fertige Bitmap rendern
Abschließend fügen wir noch die Methode „RenderBitmap“ in die Klasse ein, welche uns eine fertige Bitmap-Grafik von der Kamera liefern soll:
public Bitmap RenderBitmap()
{
int centerV = screenWidthPx / 2;
int centerW = screenHeightPx / 2;
var result = new Bitmap(screenWidthPx, screenHeightPx);
Parallel.For(0, screenHeightPx, (w) =>
{
for (int v = 0; v < screenWidthPx; v++)
{
Color c = ColorAt(v - centerV, centerW - w);
lock (result)
{
result.SetPixel(v, w, c); // ... den Pixel auf diese Farbe setzen.
}
}
});
return result;
}
Wie zuvor erklärt, liegt der Nullpunkt der Abbildungsebene genau in ihrer Mitte. Daher berechnen wir zunächst seine Koordinaten „centerV“ und „centerW“, welche jeweils die Hälfte der Bildbreite bzw. -höhe betragen. Weiterhin erstellen wir ein neues Bitmap namens „result“, in das wir unsere Szene Rendern werden. Wir starten nun zwei For-Schleifen für die Koordinaten w und v, welche jeden Pixel berechnen werden. Die äußere For-Schleife wurde dabei mit „Parallel.For“ realisiert. Dies hat zur Folge, dass das .NET Framework alle Durchläufe der Schleife gleichzeitig in eigenen Threads ausführen kann. Es kann also theoretisch für jede Pixelzeile ein eigener Thread gestartet werden, was die Berechnung merklich beschleunigt.
Die Farbe des jeweiligen Pixels berechnet die Methode „ColorAt“, wobei wir die v- und w-Koordinate vor ihrem Aufruf um centerV und centerW verschieben müssen. Die Farbe weisen wir dann mit „SetPixel“ dem jeweiligen Pixel zu. Da niemals zwei Threads gleichzeitig „SetPixel“ aufrufen dürfen, wurde dieser Aufruf mit einem „lock“ abgesichert.
Damit ist die Kamera fertig!
Weiter